Агрегирование данных (команда AGGREGATE)
Агрегирование данных (команда AGGREGATE)
Нередко на основе собранных данных необходимо получить статистические сведения об укрупненных объектах. Для этого на базе исходной матрицы создается и обрабатывается статистическим пакетом новая матрица данных.
Пример. На Рисунок 2.3 приведены данные анкетного обследовании рабочих нескольких заводов. Объекты - информация о рабочих. В данных содержится в виде переменной номер завода и номер цеха, в котором трудится респондент. На основе собранных данных вычисляется новый массив информации, в котором объектами являются цеха, признаками - статистические сведения по цехам, например, доля мужчин в цехе (в %), средний возраст и т.д. Соотношение двух массивов информации приведено на Рисунок 2.3.
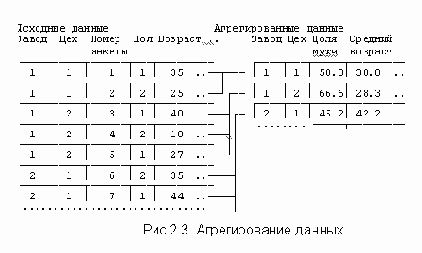
Новую матрицу агрегированных данных, организованную по тому же принципу "объект-признак", что и исходная матрица, можно получить с помощью команды AGGREGATE.
AGGREGATE /OUTFILE = 'ZECH.SPS'/BREAK ZAVOD ZECH
/PERCM = PLT(POL,2) /SRWOZR=MEAN(WOZR).
Основной способ употребления команды: подкомандой /OUTFILE указывается имя выходного файла; подкомандой /BREAK назначаются переменные "разрыва" файла данных, которыми определяются агрегируемые группы объектов. Далее записываются разделенные слэша ми "/" имена новых переменных и функции (статистики) которыми агрегируются исходные переменные, например:
Z9 "средний возраст"= MEAN(V9)/PM=PLT(V8,2).
Перед именем функции агрегирования знак равенства "=" ОБЯЗАТЕЛЕН. В списке допускается указание нескольких переменных для одной функции, в списках переменных можно использовать ключевое слово TO ( Z9 Z14= MEAN(V9 V14)/d1 to d6 = pgt(d1 to d6,0)). Число переменных в аргументе функции должно совпадать с числом новых переменных.