Переменные, порождаемые регрессионным уравнением
Переменные, порождаемые регрессионным уравнением
Сохранение переменных, порождаемых регрессией, производится подкомандой SAVE.
Благодаря полученным оценкам коэффициентов уравнения регрессии могут быть оценены прогнозные значения зависимой переменной
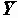
Поскольку коэффициенты регрессии - случайные величины, линия регрессии также случайна. Поэтому прогнозные значения случайны и имеют некоторое стандартное отклонение
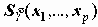
Кроме того, с учетом дисперсии остатка могут быть вычислены доверительные границы значений Y (не средних, а индивидуальных!).
Для каждого объекта может быть вычислен остаток ei=
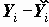
Для изучения отклонений от модели удобно использовать стандартизованный остаток - деленный на стандартную ошибку регрессии.
Случайность оценки прогнозных значений Y вносит дополнительную дисперсию в регрессионный остаток, из-за этого дисперсия остатка зависит от значений независимых переменных (
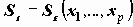
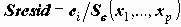
Таким образом, мы можем получить: оценку (прогнозную) значений зависимой переменной Unstandardized predicted value), ее стандартное отклонение (S.E. of mean predictions), доверительные интервалы для среднего Y(X) и для Y(X) (Prediction intervals - Mean, Individual).
Это далеко не полный перечень переменных, порождаемых SPSS.